莫烦pytorch学习笔记3
批训练
import torch
import torch.utils.data as Data
BATCH_SIZE = 8
x = torch.linspace(1, 10, 10) # x data (torch tensor) 从1到10的10个点
y = torch.linspace(10, 1, 10) # y data (torch tensor) 从10到1的10个点
#过时的方法
# torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
#现在
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True, #要不要随机打乱数据,true是要打乱
# num_workers=2, #windows去掉
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
#training...
# 打出来一些数据
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
输出,BATCH_SIZE 选为8的话,取完发现不够了,就只会把剩下的2个给你交了233
Epoch: 0 | Step: 0 | batch x: [ 7. 1. 4. 5. 9. 6. 3. 10.] | batch y: [ 4. 10. 7. 6. 2. 5. 8. 1.]
Epoch: 0 | Step: 1 | batch x: [2. 8.] | batch y: [9. 3.]
Epoch: 1 | Step: 0 | batch x: [ 2. 6. 4. 1. 5. 10. 9. 3.] | batch y: [ 9. 5. 7. 10. 6. 1. 2. 8.]
Epoch: 1 | Step: 1 | batch x: [7. 8.] | batch y: [4. 3.]
Epoch: 2 | Step: 0 | batch x: [ 9. 2. 10. 7. 4. 6. 5. 1.] | batch y: [ 2. 9. 1. 4. 7. 5. 6. 10.]
Epoch: 2 | Step: 1 | batch x: [3. 8.] | batch y: [8. 3.]
加速神经网络训练过程--优化器
多图,见莫烦
-
随机梯度下降SGD(Stochastic Gradient Descent)
-
momentum
-
AdaGrad
-
RMSProp
CNN
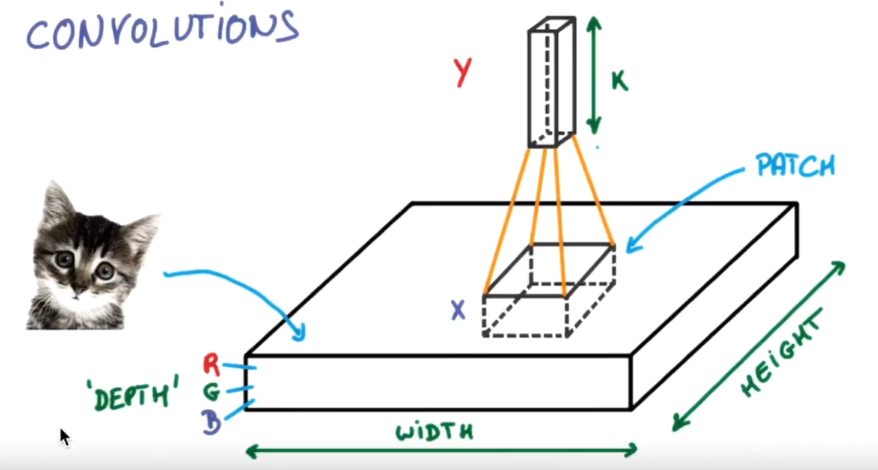
图片的长宽高,最开始的高是指RGB。
高度是指计算机用于产生颜色使用的信息,如果是黑白照片,高的单位就为1,彩色照片,就可能有多个,如红绿蓝,高度为3
过滤器就是图像中不断移动的东西,不断在图片中收集小批小批的像素块,收集完所有信息后,输出的值,可以看做是高度++,长/宽-- 图片包含一些边缘信息,同样步骤多字卷积,就有对输入图片更深的理解,将压缩和增高的信息嵌套在普通的分类神经层上,就能对这种图片进行分类了。
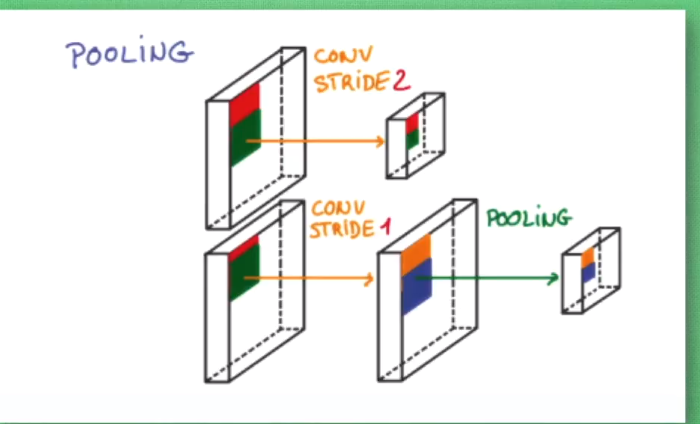
卷积的过程长宽的维度减小,深度的维度增加。
池化的作用:卷积的时候避免压缩长宽,尽量保留更多的信息,压缩的工作交给池化,这样的一项附加工作可以有效的提供准确性。
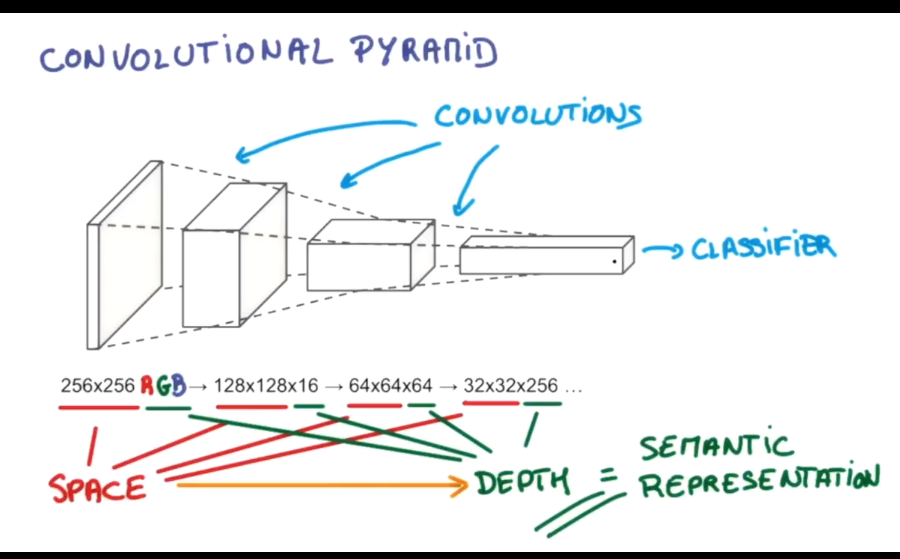
比较流行的一种搭建结构是这样, 从下到上的顺序, 首先是输入的图片(image), 经过一层卷积层 (convolution), 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式. 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,最后在接上一个分类器(classifier)进行分类预测。

CNN 卷积神经网络
包括:
- mnist手写数字
- CNN模型
- 训练
通过import torchvision可以导入数据库内容(包含需要的mnist数据集)
训练数据的时候涉及的几个基本概念:
- iteration:进行训练需要的总共的迭代次数
- epoch:一次epoch是指所有数据训练一遍的次数,epoch所代表的数字是指所有数据被训练的总论文
- batchsize:进行一次iteration(迭代)所训练数据的数量
例如:有49000个数据,计划进行十轮训练,那么epoch=10;一次训练迭代训练100个数据,batchsize=100,训练一轮总共要迭代490次(49000/100=490)。总的iteration=490*10=4900次。
- 参数和超参数:在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。 通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
- 关于channel的理解:参考--CSDN
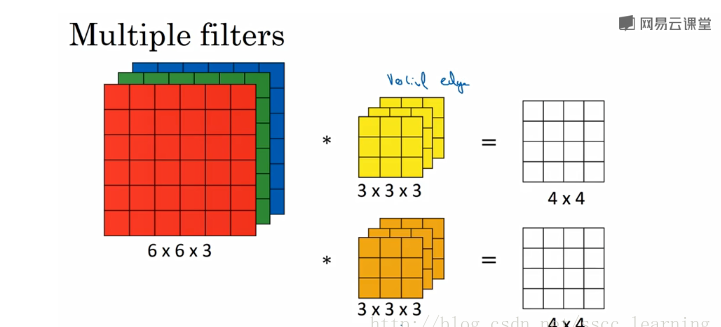
上面提到的channels分为三种
1.最初输入的图片样本的 channels ,取决于图片类型,比如RGB;
2.卷积操作完成后输出的 out_channels ,取决于卷积核的数量。此时的 out_channels 也会作为下一次卷积时的卷积核的 in_channels;
3.卷积核中的 in_channels ,刚刚2中已经说了,就是上一次卷积的 out_channels ,如果是第一次做卷积,就是1中样本图片的 channels 。
如上图,输入图片的channels为3,而卷积核中的in_channels与需要进行卷积操作的数据的channels一致,这里图片样本为3,out_channels和卷积核的个数有关,上面有两个卷积核,所以为2.
CNN关于mnist的模型,选定优化器和损失函数
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)
output = self.out(x)
return output, x # return x for visualization
cnn = CNN()
print(cnn) # net architecture
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss()